The e in Petersburg
In the decimal representation of the transcendental number e the
first occurrance of a string of 10 digits consisting of a permutation
of all 10 of the numerals 0,1,2,..,9 begins at the 1730th digit, i.e.,
the 1729th digit past the decimal point. These 10 digits are
...0719425863...
If the decimal digits of a number are regarded as essentially random,
what is the EXPECTED location of the first such occurrance? The most
direct approach to this problem is to define a Markov model with 9
states S_1, S_2,.., S_9, where S_n represents a state in which the n
most recent digits are distinct. For example, if we take the first
10 digits of e we have [2718281828], and this is in the state S_2,
because the last two digits (8 and 2) are distinct, whereas the last
three digits are not distinct (because there are two 8's).
The state of a string of digits tells us everything we need to
know about that string, i.e., from the state we can determine the
probability of transitioning to any other state when we shift one
digit to the right. This means we discard the lest-most digit and
append a new randomly chosen digit on the right. Suppose the current
string is in State 4, which means the digits look something like this
[XXXXXBDCBA]
The last four digits are distinct, A,B,C,D, but the 5th from the last
digit is B (it could also have been any of A,C, or D), so the last
five digits are not distinct. The preceding digits (denoted by X's)
don't matter. If we now discard the leftmost digit and append a new
randomly chosen numeral on the right, what are the State transition
probabilities? Since we are dealing with the base 10, there are 10
possible numerals, and if the new digit is any of the six numerals
other than A,B,C,D we will transition to State 5. This obviously has
probability 6/10. On the other hand, if the new digit is D, the state
will remain S_4, and this has probability 1/10. If the new digit is
C the state will transition to S_3, and this transition has probability
1/10, and so on. In this way we can determine the probability of the
transition from any given state to any other state, and this leads to
the transition matrix
_ _
| 1 1 1 1 1 1 1 1 1 |
| 9 1 1 1 1 1 1 1 1 |
| 0 8 1 1 1 1 1 1 1 |
1 | 0 0 7 1 1 1 1 1 1 |
M = -- | 0 0 0 6 1 1 1 1 1 |
10 | 0 0 0 0 5 1 1 1 1 |
| 0 0 0 0 0 4 1 1 1 |
| 0 0 0 0 0 0 3 1 1 |
|_ 0 0 0 0 0 0 0 2 1 _|
Given any column vector P of state probabilities, we can produce the
state probabilities for next set of digits (i.e., after moving one
place to the right) by simply multiplying by M. It's worth noting
that we have not included the "10th state" in our model, so the last
column in M doesn't sum to 1. As a result, the total probability in
the none states of our model will steadily decrease. The probability
of the 10th state is just 1 minus the probabilities of the other nine
states.
For the initial set of state probabilities P[1] we note that the
probability of a random string of 10 digits being in State k is
given by taking one of 10 choices for the last digit, one of 9 for
the 2nd to last, and so on, down to the kth from the last digit.
Then we have k choices for the "spoiler digit", which must be the
same as one of the last k (distinct) digits, and then we have 10
choices each for the remaining 10-(k+1) digits. Now, since the
total number of possible strings (of all States) is 10^10, the
probability of a given random string being in the kth State is
k 10!
P[1]_k = ---------------- (1)
(10-k)! 10^(k+1)
Of course this gives P[1]_1 = 1/10 and P[1]_10 = 10!/10^10. So, this
gives us the nine components of our initial column vector P[1]. Then
we have P[2] = M P[1], and in general
P[n+1] = M^n P[1]
If we let {P[j]} denote the sum of the components of P[j], then the
probability of having entered State 10 by the jth string of digits
is 1 - {P[j]}. Thus the probability of entering State 10 on exactly
the jth string is [1-{P[j]}] - [1-{P[j-1]}]. Hence the expected number
of strings to be examined before finding a complete permutation of the
10 numerals can be expressed as
/ \ / \
1 ( [1-{P[1]}] ) + 2 ( [1-{P[2]}] - [1-{P[1]}] )
\ / \ /
/ \ / \
+ 3 ( [1-{P[3]}] - [1-{P[2]}] ) + 4 ( [1-{P[4]}] - [1-{P[3]}] )
\ / \ /
+ ...
= 1 + {P[1]} + {P[2]} + {P[3]} + ...
= 1 + { (M^0 + M^1 + M^2 + M^3 + ...) P[1] }
The sum of the geometric series of transition matrices is (I-M)^-1,
and so if we let R denote the row vector
R = [1 1 1 1 1 1 1 1 1]^T
we have the expected number E(B) of digits for the base B=10
-1
E(B) = 1 + R (I+M) P = 3526013/1134
= 3109.358906526...
This same method can obviously be applied to other bases. In general
for the base B we we define the arrays and vectors with indices ranging
from 1 to B
/ 1 if m=n
I[m,n] = ( Identity matrix
\ 0 if m != n
/ B-n if n = m-1
M[m,n] = ( 1 if n > m-1 Transition matrix
\ 0 if n < m-1
m B!
P[m] = -------------- State column vector
(B-m)! B^(m+1)
In terms of these matrices the expected number of digits for the
base B is
E(B) = 1 + R (I-M)^-1 P
The table below shows the result for bases from 2 to 20.
E(B)
------
B E(B) E(B-1) E(B) (B-1)! E(B)
--- ------------ -------- ------------------ ------------
2 2.0000 2 2
3 5.0000 2.5000 5 10
4 12.6666 2.5333 38/3 76
5 31.5833 2.4934 379/12 758
6 78.2000 2.4759 391/5 9384
7 194.0722 2.4817 34933/180 139732
8 485.0984 2.4995 152806/315 2444896
9 1223.0468 2.5212 78275/64 49313250
10 3109.3589 2.5423 3526013/1134 1128324160
11 7963.0504 2.5609 3612039703/453600 28896317624
12 20520.0176 2.5769
13 53151.9215 2.5902
14 138270.8627 2.6014
15 361004.9270 2.6108
16 945426.8069 2.6188
17 2482475.8890 2.6257
18 6533289.2310 2.6317
19 17228381.2502 2.6370
20 45511474.3001 2.6416
Notice that E(B) increases by a factor of about 2.5 or a bit more on
each step. It's tempting to conjecture that the asymptotic ratio of
successive values of E(B) is e.
It's also interesting to explore other ways of approaching this
problem, even if they only give approximate answers. For example,
we might estimate that the MEAN location of the first occurrance is
roughly 3060, taking into account the fact that such occurrances tend
to be clustered more than would be expected if each sequence of 10
digits was independent. (They are not independent because they
overlap.) If we let q denote the quantity 10!/(10^10), then the
inclusion/exclusion principle gives the following probabilities that
the first n sets of 10 digits (i.e., the first n+9 digits) contains
a complete permutation string
Inc-Exc
n [1-(1-q)^n]/q Prob/q
1 1.0000.. 1
2 1.9996.. 1.9
3 2.9989.. 2.79
4 3.9978.. 3.677
5 4.9964.. 4.5627
6 5.9946.. 5.44769
7 6.9924.. 6.332219
8 7.9898.. 7.2164033
9 8.9869.. 8.10029...
10 9.9836.. 8.9839....
20 19.9312.. 17.8045....
100 98.2248.. < 87.61
400 372.3874 < 335.20
1000 838.7784 < 775.28
These values agree exactly with the results of the Markov model.
The center column gives the probabilities based on the assumption
that each string of 10 digits is independent, which gives a
population with a mean of about -1/ln(1-q) = 2755.23. In contrast,
the actual probabilities, taking into account the dependence of
overlapping strings, gives a cumulative probability approaching
1 - e^(-rn) where r is approximately 1/3062. Thus the mean location
of the first occurrance is about 3062. If we generate sequences of
"random" decimal digits and make 5 runs of 5000 trials each, using a
different random number generator for each run, we get the average
results 3044, 3062, 3045, 3068, and 3074, for an overall mean of
3058.6. Notice that this appears to be systematically less than the
exact value of 3109.35 given by the Markov model.
To explain this, it's useful to examine the probabilities of having
found a complete permutation after examining the first n sets of 10
consecutive digits. We can compute a table of values using the
recurrence P[n+1] = M^n P[1] for the column vectors P[j], and then
letting P(j) = 1 - SUM P[j] denote the cumulative probability of
having reached the 10th state. Several values are tabulated below,
and they agree exactly with the inclusion/exclusion values. (Note
that the tabulated values are the probabilities divided by
q = 10!/10^10.)
n P(n)/q
----- ------------
1 1.0000000
2 1.9000000
3 2.7900000
4 3.6770000
5 4.5627000
6 5.4476900
7 6.3322190
8 7.2164033
... ...
24 21.325
56 49.325
120 104.468
248 211.405
504 412.515
1016 768.302
2040 1326.014
4088 2015.841
8184 2557.570
16376 2741.519
32760 2755.658
65528 2755.731
One method for quickly estimating the expected value of the number
of strings from this table would be to observe that the cumulative
probabilities P(n) of being in the 10th state have virtually an
exponential distribution, i.e., P(n) = 1 - exp(-rn) where r is the
"rate". Taking the value of
P(1016) = 768.302*q = 1 - exp(-1016*r)
we can compute the expected value (assuming an exponential
distribution)
1 n
E = ---- = ----------------- = 3108.544
r -ln(1-768.302*q)
which is extremely close to the value of 3109. The result is
virtually the same for any n>500 or so. However, the method is very
sensitive to the value of P(n). I had previously estimated P(1000)
as being slightly less than 775 based on just the first 3 terms of
the inclusion/exclusion formula. This is fairly accurate, but if I
compute a rate from this value it comes out as r = 1/3028.
The explanation for the "systematic error" is that while E_inf[n]
is 3109, the expected value for trials of 18600 digits or fewer is
E_18600[n] = 3062. The random number generator determined the
expected values out of 25000 trials and not a single one exceeded
18600 digits, so it isn't surprising that the results underestimate
the true theoretical value. We would have needed to run many more
trials to get the theoretical result. There's a strong resemblence
to the Petersburg Paradox here, because the theoretical expected
value is forced up by some extremely unlikely outcomes that we may
never observe "in practice".
As an example, if we examine the first 2 million digits of the number
e, we find that there are 761 occurrances of complete permutations on
10 consecutive digits, which implies that the mean "distance" between
occurrances is only about 2585 digits. This is shown in the plot
below (using digits of e computed by Nemiroff & Bonnell):
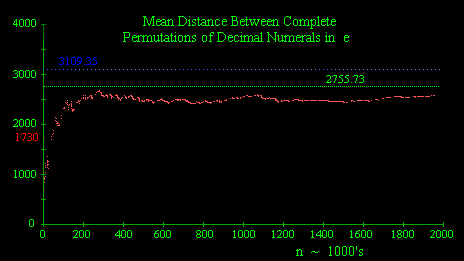 The reason the expected time for the first occurrance (3109.35)
is greater than the mean time between occurrances is that these
occurrances are not independent. Indeed, the 2nd and 3rd complete
permutations of decimal numerals in e are on consecutive strings of
10 digits. In other words, the occurrances tend to occur in "clumps",
and so there are more and longer "dry spells" than we would expect
based on the average frequency of occurrence if the events were
independent. To generate the closed-loop response of this system
we use the complete 10x10 transition matrix
_ _
| 1 1 1 1 1 1 1 1 1 1 |
| 9 1 1 1 1 1 1 1 1 1 |
| 0 8 1 1 1 1 1 1 1 1 |
1 | 0 0 7 1 1 1 1 1 1 1 |
N = -- | 0 0 0 6 1 1 1 1 1 1 |
10 | 0 0 0 0 5 1 1 1 1 1 |
| 0 0 0 0 0 4 1 1 1 1 |
| 0 0 0 0 0 0 3 1 1 1 |
| 0 0 0 0 0 0 0 2 1 1 |
|_ 0 0 0 0 0 0 0 0 1 1 _|
Then from any initial state vector P[0] the state vector after k
steps is
P[k] = N^k P[0]
If we take as our initial state vector P the a_priori probabilities
for the states given by equation (1), then we find that this is the
equilibrium condition, i.e., we have N^k P = P for all k, which
shows that P is an eigenvector for every N^k. As k increases the
columns of N^k approach P.
Hence this state vector P gives the probabilities for being found in
any of the 10 states on a randomly selected string. Consequently we
would expect the frequency of being in state 10 to correspond with
a mean steps between occurrences of 1/P_10 = 2755.73. This differs
from the actual mean (2585) over the first 2 million steps by about
6.1 percent. In contrast, if we check the first million digits of
the number pi (using digits computed by Duane Bailey) we find
excellent agreement with the predicted value of 2755, as shown below:
The reason the expected time for the first occurrance (3109.35)
is greater than the mean time between occurrances is that these
occurrances are not independent. Indeed, the 2nd and 3rd complete
permutations of decimal numerals in e are on consecutive strings of
10 digits. In other words, the occurrances tend to occur in "clumps",
and so there are more and longer "dry spells" than we would expect
based on the average frequency of occurrence if the events were
independent. To generate the closed-loop response of this system
we use the complete 10x10 transition matrix
_ _
| 1 1 1 1 1 1 1 1 1 1 |
| 9 1 1 1 1 1 1 1 1 1 |
| 0 8 1 1 1 1 1 1 1 1 |
1 | 0 0 7 1 1 1 1 1 1 1 |
N = -- | 0 0 0 6 1 1 1 1 1 1 |
10 | 0 0 0 0 5 1 1 1 1 1 |
| 0 0 0 0 0 4 1 1 1 1 |
| 0 0 0 0 0 0 3 1 1 1 |
| 0 0 0 0 0 0 0 2 1 1 |
|_ 0 0 0 0 0 0 0 0 1 1 _|
Then from any initial state vector P[0] the state vector after k
steps is
P[k] = N^k P[0]
If we take as our initial state vector P the a_priori probabilities
for the states given by equation (1), then we find that this is the
equilibrium condition, i.e., we have N^k P = P for all k, which
shows that P is an eigenvector for every N^k. As k increases the
columns of N^k approach P.
Hence this state vector P gives the probabilities for being found in
any of the 10 states on a randomly selected string. Consequently we
would expect the frequency of being in state 10 to correspond with
a mean steps between occurrences of 1/P_10 = 2755.73. This differs
from the actual mean (2585) over the first 2 million steps by about
6.1 percent. In contrast, if we check the first million digits of
the number pi (using digits computed by Duane Bailey) we find
excellent agreement with the predicted value of 2755, as shown below:
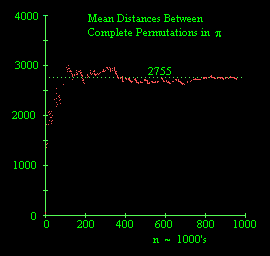 Since the decimal digits of e are presumed to be normally distributed,
the 6.1% discrepancy in the frequency of complete permutations led
me to suspect that there might be a systematic error on the digits of
e computed by Nemiroff & Bonnell, so I acquired another set of digits
computed independently by James Davis, but the result agree exactly
with the set from Nemiroff & Bonnell. So, it seems that the decimal
digits of e really do exhibit a statistically significant non-
normality.
Since the decimal digits of e are presumed to be normally distributed,
the 6.1% discrepancy in the frequency of complete permutations led
me to suspect that there might be a systematic error on the digits of
e computed by Nemiroff & Bonnell, so I acquired another set of digits
computed independently by James Davis, but the result agree exactly
with the set from Nemiroff & Bonnell. So, it seems that the decimal
digits of e really do exhibit a statistically significant non-
normality.
Return to MathPages Main Menu
Сайт управляется системой
uCoz